

最近話題の『音声ディープフェイク』。
特に注目されているのが、話者の声をリアルに再現できる『XTTS』と『RVC(Retrieval-based Voice Conversion)』です。
 もりんさん
もりんさん今回はちょっと上級者向けの記事になります。初心者でもできないことはありませんよ!挑戦してみてくださいね
でも、それぞれ何が違うの?どっちが簡単?精度は?
この記事では、両者の違いや特徴をわかりやすく比較し、どちらがあなたに合っているかを丁寧に解説していきます。
声を使った創作やフェイク動画に興味がある方は、ぜひ参考にしてみてくださいね。
XTTSとRVCとは?
『XTTS』と『RVC』は、どちらも音声を合成・変換するための便利なツールです。
でも、それぞれがどんな役割を持っているのか、意外と知られていません。
ここではまず、それぞれの基本的な特徴をやさしく解説していきますね。
XTTSとは?
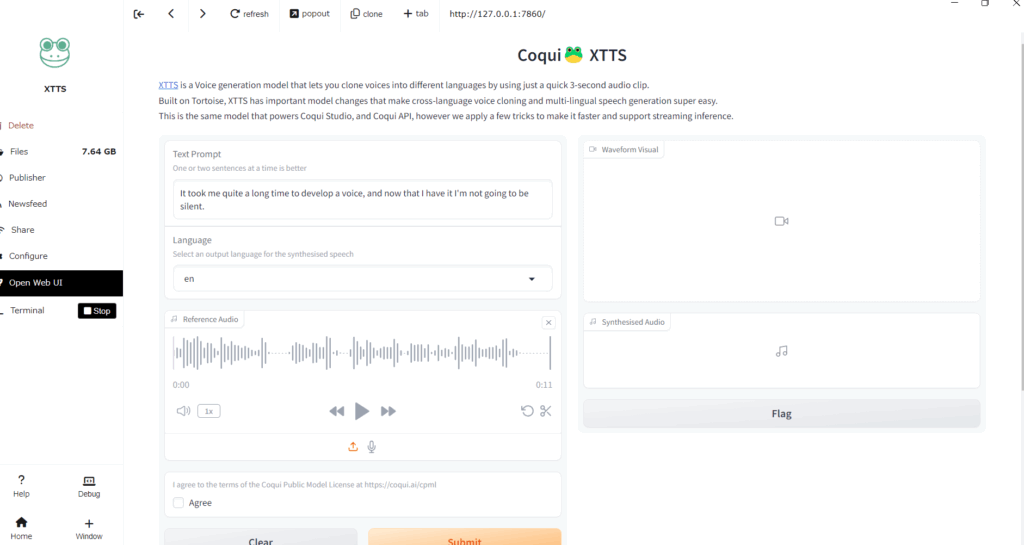
XTTSは、テキストを入力するだけで人間のような音声を作り出せる『TTS(Text-to-Speech)』ツールです。
開発したのは『Coqui』というオープンソースプロジェクトで、無料で使えるのがうれしいポイントです。
文字を入力すると、すぐに自然な話し方で音声が生成されます。
しかも、複数の話者の声に対応していて、感情まで込めることができるんです。
たとえば、やさしく話す声や、ちょっと怒っているような声まで表現できます。
英語や日本語など、複数の言語に対応しているのも特徴です。
声のベースはあらかじめ用意されているので、難しい設定をしなくてもすぐに始められます。
初心者でも安心して使える、とても親しみやすいツールです。
ポイントまとめ
・文字入力だけで音声が作れる
・感情や言語も調整できる
・初心者でもすぐ使える設計
RVCとは?
RVCは、既存の音声を別の声に変換する『音声変換(Voice Conversion)』のためのツールです。
たとえば、自分の声を有名人の声にそっくり変える、そんな使い方ができるのが特徴です。
ただし、その声を使うためには、あらかじめ音声データを学習させる必要があります。
ある程度まとまったデータを用意して、それをもとに機械に『この人の声はこんな音だよ』と教えていくんです。
学習が終われば、好きな音声をその人の声に変えることができます。
歌声の変換や、ナレーションの声真似など、応用範囲はとても広いです。
ただし、精度を出すには多少の知識や調整が必要になることもあります。
その分、完成した音声はとてもリアルで、聞いた人が驚くほどのクオリティになります。
ポイントまとめ
・元音声を別の声に変換できる
・声の学習が必要になる
・リアルな仕上がりを目指せる
XTTSとRVCの機能の違いってなに?
XTTSとRVCは、どちらも『音声に関するツール』ではありますが、その機能やできることはまったく違います。
ここでは、それぞれがどんな作業に向いているのか、何ができるのかを具体的に比べてみましょう。
XTTSの主な機能
XTTSの最大の特徴は『テキストをそのまま音声に変える』というシンプルさです。
たとえば「こんにちは、今日はいい天気ですね」と打ち込めば、その言葉を自然な声で読み上げてくれます。
さらに、話すスピードや声の高さ、感情表現なども細かく調整できるので、自分の好みにあった読み方に仕上げることができます。
複数の話者に対応しており、声の切り替えも簡単です。
設定画面もわかりやすく、初心者でもすぐにナレーション音声が作れます。
AI音声をナレーションに使いたい人にとっては、まさに理想的なツールです。
ポイントまとめ
・テキストをそのまま音声化
・感情や声の高さも調整可能
・複数の話者に対応している
RVCの主な機能
RVCは『元の音声を別の声に変換する』ことに特化したツールです。
たとえば、自分の声で「おはよう」と言った音声を、学習させた声(有名人やアニメキャラなど)にそっくり変えることができます。
そのためには、まず対象の声を学習させる必要があります。
声のデータを集めてモデルを作り、そのモデルをもとに変換処理を行う流れになります。
学習が終わったあとは、元の音声と同じセリフをまったく違う声で再生できるので、リアルな声真似やボイスチェンジに最適です。
歌声も変換可能なので、VtuberやAIカバー曲制作などにもよく使われています。
ポイントまとめ
・音声を別の声に変換できる
・声のモデルを自分で学習させる必要がある
・歌や会話など幅広い変換に対応している
使いやすさの違い
機能がどんなに優れていても、実際に使うときに難しければ意味がありませんよね。
ここでは、XTTSとRVCの『使いやすさ』について、実際に触ってみた印象をもとに比べてみましょう。
XTTSの使いやすさ
XTTSは、とにかく最初の一歩が軽いんです。
Google Colab上で用意されたノートブックを開くだけで、すぐに音声生成が始められます。
専用のソフトをPCにインストールしたり、難しい設定をする必要はありません。
画面に表示された入力欄にテキストを打ち込んで、ボタンを押すだけ。
それだけで、まるで人間が話しているような自然な音声が生成されるので、初めて使ったときは感動しました。
声の種類や話し方も、数値を変えるだけで簡単に調整できるので、自分好みの音声がすぐに作れます。
とにかく手軽に音声を作ってみたいという人には、XTTSがぴったりです。
ポイントまとめ
・Colabで動かせてインストール不要
・入力と実行だけで音声が作れる
・調整も直感的でわかりやすい
RVCの使いやすさ
RVCは、正直に言うと少しハードルが高めです。
まず最初に、環境を整える必要があります。
Pythonやffmpeg、GPUの設定など、少しだけ技術的な知識が求められます。
それから、変換に使いたい声の音声データを準備し、それを使ってモデルを学習させる必要があります。
この『学習』の部分がちょっと大変で、場合によっては1〜2時間以上かかることも。
でも、その工程を乗り越えると、完成度の高い音声変換ができるようになります。
一度学習させてしまえば、WebUIで音声ファイルを選んで変換ボタンを押すだけで、別の声に変換できます。
最初の準備は少し手間ですが、慣れてしまえば自由自在に『声を操る』楽しさが味わえます。
ポイントまとめ
・最初に環境構築と学習作業が必要
・やや技術的だが自由度は高い
・慣れると高精度な変換が簡単にできる
精度・リアルさの違い
音声ツールを選ぶうえで大切なのが『どれだけ人間らしく聞こえるか』という精度やリアルさです。
どんなに操作が簡単でも、機械っぽい音声では魅力が半減してしまいますよね。
ここでは、XTTSとRVCがどれほど自然に話せるのか、それぞれの音質やリアリティの違いについて詳しく見ていきましょう。
XTTSの精度・リアルさ
XTTSは、最新のTTS技術が使われているため、合成音声とは思えないほど滑らかです。
一言一言がクリアで、イントネーションにも自然な抑揚があります。
とくに感情表現が得意で、『やさしい声』『怒った声』『落ち着いた語り』など、セリフの雰囲気に合わせた声づくりができます。
話すスピードやトーンも細かく設定できるので、聞き手に合わせた調整がしやすいのもポイントです。
ただし、あくまでも『人工的に作られた声』なので、完全に実在の人物とそっくりにするのは難しいです。
でも、『ナレーション』『朗読』『解説動画』などには十分すぎるほど自然で、むしろTTSならではの安定感が活きてきます。
ポイントまとめ
・抑揚や間の取り方が自然で聞きやすい
・感情を込めた読み上げが得意
・完全なモノマネは難しいが汎用性は高い
RVCの精度・リアルさ
RVCのすごいところは、元になる音声をもとに『本物のような声』に変換できる点です。
たとえば、有名人の声を学習させれば、その人が喋っているような音声が作れてしまいます。
しかも、元の発声のリズムやテンポを保ったまま、そっくりの声に置き換えられるので違和感がとても少ないです。
歌声も自然に変換できるため、YouTubeで流行っているAIカバー曲などにも多く使われています。
ただし、精度は元音声の質や学習量に大きく左右されるため、うまくいかない場合はノイズが混じったり、言葉が聞き取りづらくなることもあります。
逆にいえば、丁寧に学習データを準備すれば、まるで本物のような完成度の音声を作ることも可能です。
ポイントまとめ
・本人そっくりの声を再現できる
・リズムや抑揚も自然に保たれる
・元音声と学習精度によって仕上がりが左右される
向いている用途
XTTSとRVCは、それぞれまったく違うアプローチで音声を作り出します。
そのため、どちらが向いているかは『どう使いたいか』によって大きく変わってきます。
ここでは、どんな目的にどちらのツールが合っているのかを、具体的なケースに分けて紹介しますね。
XTTSが向いている用途
XTTSは『ナレーションを作る』『読み上げ音声を用意したい』というときにぴったりです。
たとえば、YouTube動画の解説や、商品紹介のナレーション、教育コンテンツの朗読など、安定して落ち着いた声が必要な場面に最適です。
テキストを打ち込めばすぐに音声化できるので、スクリプトがあれば10分で収録が完了するような手軽さがあります。
また、感情表現もできるため、物語の朗読やセリフ付きの動画などにも応用できます。
声優を雇うほどではないけれど、質のいい音声が欲しい──そんなときに重宝されるツールです。
ポイントまとめ
・YouTubeのナレーションや解説動画に最適
・スピーディーに音声が必要なときに便利
・感情のある朗読やセリフにも対応できる
RVCが向いている用途
RVCは『本人そっくりの声を使いたい』『リアルな声真似をしたい』というときに抜群の効果を発揮します。
たとえば、Vtuberのボイスチェンジ、歌ってみた動画のAIカバー、推しキャラの声真似、あるいはネタ系のフェイク動画など。
もともとある音声を変換する形式なので、歌やセリフのタイミング・抑揚などがそのまま生きるのが強みです。
学習モデルをしっかり作れば、リスナーが本物と聞き間違うほどの完成度にもなります。
ただし、用途によっては著作権や肖像権の配慮が必要な場面もあるので、使うときにはマナーとルールも大切にしてくださいね。
ポイントまとめ
・AIカバー曲やVtuberの声変換に最適
・本人の声にそっくりなフェイク音声が作れる
・ネタ系・創作系の用途に強いが倫理面にも注意
どちらを選ぶべき?
ここまで読んでくださった方は、XTTSとRVCの違いがだいぶ見えてきたのではないでしょうか。
とはいえ、結局『自分にはどっちが合っているの?』と迷う方も多いと思います。
そこで最後に、目的やスキルに応じてどちらを選ぶべきかを、やさしく整理してお伝えしますね。
XTTSがおすすめな人
『手軽に音声を作りたい』『ナレーション音声が欲しい』『文章をすぐ読み上げたい』
そんなふうに思っている人には、迷わずXTTSがおすすめです。
インストールや難しい準備がいらないので、AI初心者や動画編集初心者でもすぐに使えます。
とくに、YouTube用の原稿読み上げや、ナレーション入りの資料をサクッと作りたい人にとっては、理想的なツールです。
スクリプトがある程度できていれば、数分で音声完成。
作業の時短にもなって、かなり頼れる存在になります。
ポイントまとめ
・初心者でもすぐに使いたい人向け
・読み上げ音声を安定して作れる
・動画や教材のナレーションに最適
RVCがおすすめな人
『本人そっくりの声を作りたい』『変換の精度にこだわりたい』『ちょっと手間をかけてもいいから面白いことがしたい』
そんなあなたには、RVCがぴったりです。
確かに最初の環境構築やモデル学習は少し手間がかかりますが、それを乗り越えると一気に表現の幅が広がります。
とくに、声の精度やリアルさを求める場合、RVCの自由度と再現力は他にない強みです。
フェイク動画、音声作品、ボイスチェンジなどで遊びたい人には、心からおすすめできるツールです。
ポイントまとめ
・声の精度や本人再現にこだわる人向け
・変換後の完成度に満足したい人に最適
・音声で遊びたい人、創作したい人にぴったり
| 比較項目 | XTTS | RVC |
|---|---|---|
| 入力方法 | テキスト | 音声ファイル |
| 出力音声 | 合成音声(読み上げ) | 変換音声(原音あり) |
| 声の元データ | プリセット or 自作 | 自分で収集・学習が必要 |
| 感情表現 | 可能 | 限定的(原音に依存) |
| 学習工程 | ほぼ不要(即使用可) | 学習必須(時間と手間) |
ディープフェイク用途におけるXTTS vs RVC徹底比較表
リアルな偽音声を作る『ディープフェイク』の分野では、XTTSとRVCのどちらを使うかが成果を大きく左右します。
『本人そっくりの声で喋らせたい』のか、それとも『ナレーション風に自然に読ませたい』のか。
目的によって選ぶべきツールは変わってくるんです。
ここでは、ディープフェイクとして音声を作ることを前提に、再現度・使いやすさ・変換の自由度など、重要なポイントを徹底比較してみました。
それぞれの特徴を見ながら、自分に合ったツールを見つけてみてくださいね。
| 比較ポイント | XTTS(テキスト読み上げ) | RVC(声の変換) |
|---|---|---|
| 本人そっくり度 | 低め(誰かの声っぽいけど似てはいない) | 高い(学習次第でそっくりな偽声が作れる) |
| 歌の対応 | ほぼ不向き(ナレーション専用) | 非常に得意(AIカバー曲や歌ってみたに多数使用) |
| 感情表現の自由度 | 高め(怒り・喜びなどを数値で調整可能) | 元音声に依存(自分で感情を込めて話す必要あり) |
| ため息・笑い声など | 不自然になりやすい(スクリプト次第) | 変換元に入れればリアルに出せる |
| 操作の手軽さ | とても簡単(コピペ操作でOK) | やや難しい(Python・ffmpeg・学習が必要) |
| 即時性(すぐ作れるか) | ◎(10秒以内で音声生成) | △(モデルがあれば可能。なければ学習が必要) |
| 必要な素材 | テキストだけでOK | 自分の音声+学習用音声 |
| ナレーション用途 | 得意(落ち着いた自然音声) | 向いていない(感情制御がしづらい) |
| SNS向けネタ動画 | ナレーションやネタ風読み上げに便利 | 『本人が喋ってる!?』という驚きを狙える |
| 歌+しゃべり両方したい | 難しい(音程制御なし) | 可能(歌って喋れる万能型) |
ディープフェイクに特化して比べると、本人そっくりの偽音声を作りたいならRVCが圧勝です。
声の学習によって、本物と聞き間違えるほどのリアルな変換ができます。
一方で、XTTSは簡単に自然なナレーションを作るのが得意ですが、声真似には向きません。
感情表現や読み上げの安定感はあるものの、ディープフェイクとしての破壊力はRVCに軍配が上がります。
手軽さを取るならXTTS、リアルさとインパクト重視ならRVCが最適です。
まとめ
ディープフェイク音声を作りたいとき、XTTSとRVCはまったく違う強みを持ったツールです。
XTTSは、テキストを入力するだけで自然なナレーション風の音声がすぐに作れる、手軽でスピーディーなTTSツールです。
感情表現もある程度コントロールでき、解説動画や商品紹介などに向いていますが、本人そっくりの声を出すには向いていません。
一方のRVCは、元の音声を誰かの声にそっくり変換できる、本格派のディープフェイク向けツールです。
ため息や笑い声、歌などもリアルに変換できるため、本人のような“人間味”まで再現できます。
ただし、準備や学習に手間がかかるため、ある程度技術に慣れた人向けといえるでしょう。
結論として手軽に作りたいならXTTS、本物のような声で驚かせたいならRVC
自分の目的やスキルに合わせて、ベストなツールを選んでみてくださいね。


のアバターがすごすぎた!実際にAIアバターを作ってみた結果をレビューしていきます!-1-1024x538.png)

でガンガン売れるグッズ販売!|ゼロからのやさしいガイド-300x158.png)
の学び放題がすごい!実際、講座を付けてみた感想!-300x158.png)

のアバターがすごすぎた!実際にAIアバターを作ってみた結果をレビューしていきます!-1-300x158.png)





